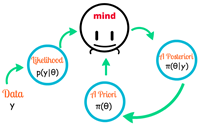
Bayesian hierarchical models enjoy flexibility in model construction and accommodation of complex data structures. The research in this area spans a diversity of applications, ranging from psychological and behavioral science studies, high throughput data analysis, spatial-temporal analysis of longitudinal and survival data. Currently, we are constructing spatial-temporal predictive models to study intervention effect in economic observational studies with small sample size and heterogeneous spatial structure. Another project is to study prediction and uncertainty quantification of high-dimensional multi-type data with block-wise missing structure.
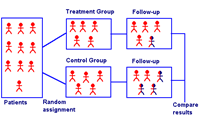 Clinical trial design
Clinical trial designRandomized trials with correlated outcomes are widely employed in medical, epidemiological, and behavioral studies. Correlated outcomes are usually categorized into two types: clustered and longitudinal. The former arises from trials where randomization is performed at the level of some aggregate (e.g., clinics) of research subjects (e.g., patients). The latter arises when the outcome is measured multiple times during follow-up from each subject. In addition, missing data is a common issue which leads to the challenge of “partial” observations. The research is to develop GEE-based sample size methods that cover various types of correlated outcomes (continuous, binary, and count) and accommodate missing data, correlation structures, and financial constraints. Trials based on such outcomes, although more complicated than the conventional randomized trials, offer greater flexibility and efficiency in practice.
 Machine learning and sentiment analysis
Machine learning and sentiment analysisMachine learning (ML) has enjoyed great success in prediction and classification using big data. However, the desirable accuracy from ML algorithms often goes hand in hand with lack of interpretability due to their complex inner-workings. In practice, it can be a limitation because interpretability is crucial for understanding and acceptance of prediction or classification outcomes. To meet this challenge, we try to incorporate machine learning components, such as the attention mechanism, into a relatively simpler parametric statistical model structure. We have applied the idea in the text sentiment analysis. By combining the attention mechanism from ML (which is capable of providing meaningful word embedding vectors) with a relatively simple interpretable statistical model, we are able to get the best of both worlds: the interpretability of a statistical model and the high predictive performance of ML algorithms.